4.4.6.12. Resources¶
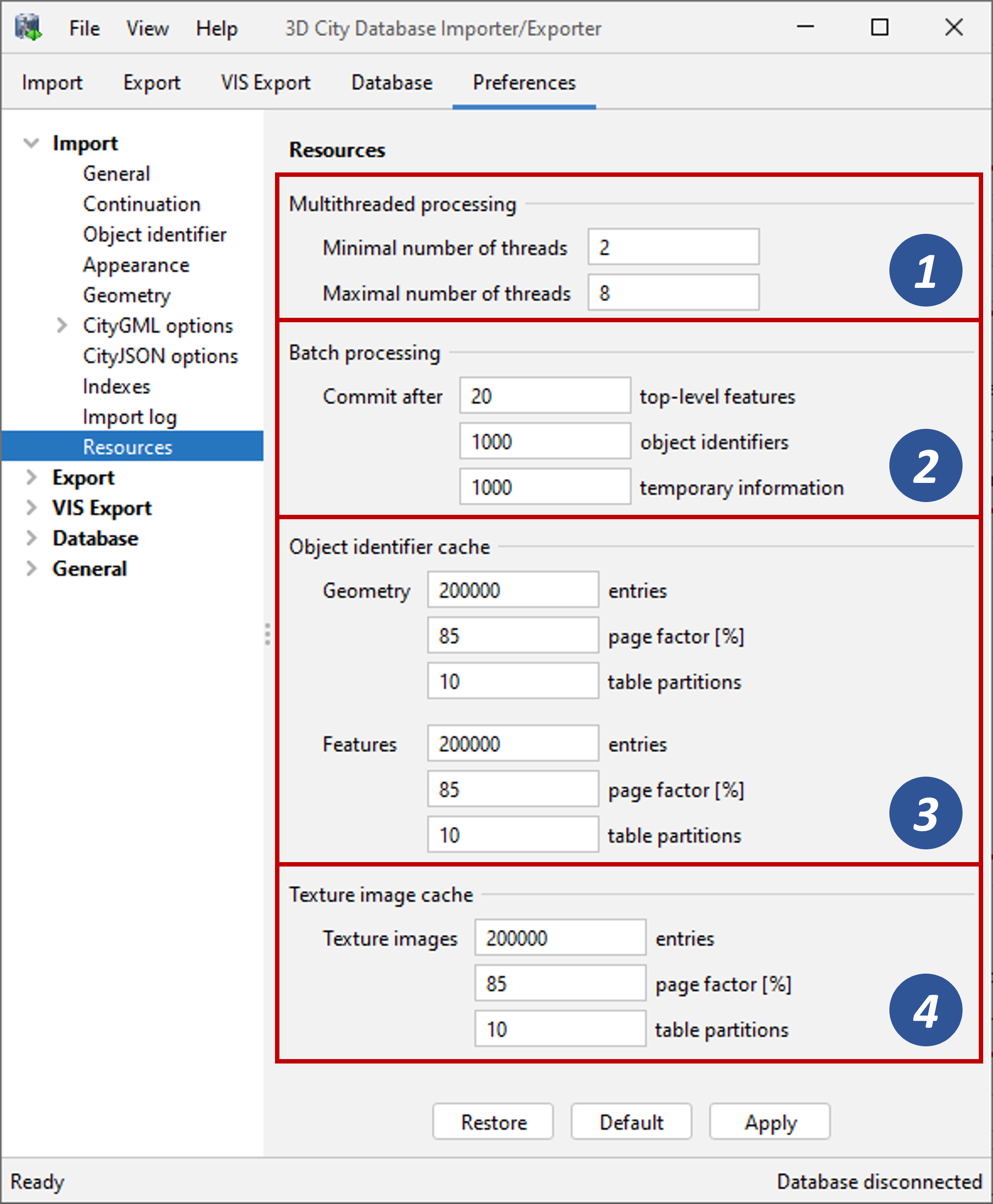
Fig. 4.31 Import preferences – Resources.
Multithreading settings
The software architecture of the Importer/Exporter is based on multithreading. Put simply, the different tasks of an import process are carried out by separate threads. The decoupling of compute bound from I/O bound tasks and their parallel non-blocking processing usually leads to an increase of the overall application performance. For example, threads waiting for database response do not block threads parsing the input document or processing the CityGML/CityJSON input features. In a multi-core environment, threads can even be executed simultaneously on multiple CPUs or cores.
The Resource settings allow for controlling the minimum and maximum number of concurrent threads during import [1]. Make sure to enter reasonable values depending on your hardware configuration. By default, the maximum number is set to the number of available CPUs/cores times two.
Caution
A higher number of threads does not necessarily result in a better performance. In contrast, a too high number of active threads faces disadvantages such as thread life-cycle overhead and resource thrashing. Also note that each thread requires its own physical connection to the database. Therefore, your database must be ready to handle enough parallel physical connections. Ask you database administrator for assistance.
Batch processing
In order to optimize database response times, multiple database statements are submitted to the database in a single request (batch processing). This allows for an efficient data processing on the database side. The user can influence the number of SQL statements in one batch through the settings dialog [2]. The dialog differentiates between batch sizes for top-level features (default: 20) and cache entries for object identifiers and temporary XLink information (default: 1000 each).
Note
All database operations within one batch are buffered in main memory before being submitted to the database. Thus, the Importer/Exporter might run out of memory if the batch size is too high (see Section 4.1 for how to increase the available main memory). After a batch is submitted, the transaction is committed.
Cache settings
The Importer/Exporter employs strategies for parsing CityGML datasets of arbitrary file size and for resolving XLink references. A naive approach for XLink resolving would read the entire CityGML dataset into main memory. However, CityGML datasets quickly become too big to fit into main memory. For this reason, the import process follows a two-phase strategy:
In a first run, features are written to the database neglecting references to remote objects. If a feature contains an XLink though, any context information about the XLink is written to temporary database tables. This information comprises, for instance, the table name and primary key of the referencing feature/geometry instance as well as the identifier (gml:id) of the target object. In addition, while parsing the document, the import process keeps track of every encountered gml:id as well as the table name and primary key of the corresponding object in database. It is important to record this information because it cannot be predicted a priori whether or not a gml:id is referenced by an XLink from somewhere else in the document. In order to ensure fast access, the information is cached in memory. If the maximum cache size is reached, the cache is drained to temporary database tables to prevent memory overflows.
In a second run, the temporary tables containing the context information about XLinks are revisited and queried. Since the entire CityGML document has been processed at this point in time, valid references can be resolved and processed accordingly. With the help of the object identifier cache, the referenced objects can be quickly identified within the database.
The caching and paging behaviour for object identifiers can be influenced via the Resource preferences [3]. The dialog lets a user enter the maximum number of identifiers to be held in main memory (default: 200,000 entries), the percentage of entries that will be written to the database if the cache limit is reached (page factor, default: 85%), as well as the number of parallel temporary tables used for paging (table partitions, default: 10). The Importer/Exporter uses separate caches for identifiers of geometries and features [3]. Moreover, a third cache is used for handling texture atlases and offers similar settings [4].
Note
By default, the temporary tables for draining the caches are created in the same 3D City Database instance. You can also choose to use a local cache instead (see Section 4.7.3 for more details). However, note that some temporary information must be stored in the database even if you use a local cache to be able to perform JOINs between temporary tables and tables of the 3DCityDB schema.